
AI写代码越快,系统越容易失控?工程师必须直面这个悖论
- 2026-05-26 09:00:00
- 翰德恩咨询 原创
- 28
越来越多的研发团队正在经历同一种困惑:引入AI编码工具之后,代码交付速度明显提升,但线上问题变多了,技术债越堆越厚,系统越来越难以维护。
问题不在工具,在工程体系没有跟上。
AI带来的,是一种全新的不确定性
传统软件工程建立在确定性之上——同样的输入,必然产生同样的输出。大语言模型打破了这个规则:相同指令可能产生不同实现路径,错误表述难以客观验证,代码修改容易引发非预期关联变更。研发链路里,第一次出现了大规模的非确定性协作者。
因此,当前对AI研发的讨论,不应停留在"模型能不能替代程序员",而应转向更务实的工程问题:非确定性的输出如何融入确定性的验证体系?模型犯的错误能不能转化成系统约束?高风险操作有没有不可逾越的权限边界?
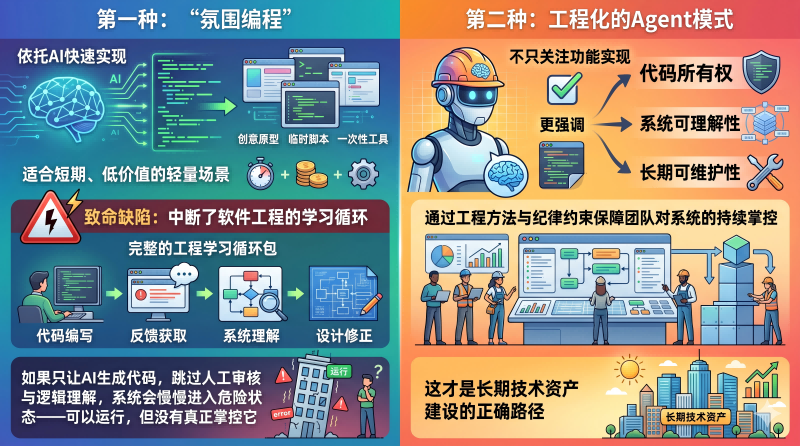
两种编码模式,不能混为一谈
当前AI辅助编程大致分为两种模式,混淆使用是许多团队踩坑的根本原因。
第一种是"氛围编程"依托AI快速实现创意原型、临时脚本、一次性工具,适合短期、低价值的轻量场景。但它有一个致命缺陷:中断了软件工程的学习循环。完整的工程学习循环包含代码编写、反馈获取、系统理解、设计修正等环节。如果只让AI生成代码,跳过人工审核与逻辑理解,系统会慢慢进入危险状态——可以运行,但没有人真正掌控它。
第二种是工程化的Agent模式,不只关注功能实现,更强调代码所有权、系统可理解性和长期可维护性,通过工程方法与纪律约束保障团队对系统的持续掌控。这才是长期技术资产建设的正确路径。
传统工程实践,在AI时代反而更重要
AI生成效率越高,传统工程实践的兜底价值越大。"小粒度变更提交"在AI时代被赋予新意义——它不只是代码管理习惯,更是限制模型发散、降低审核成本、提升回滚效率的有效手段。
AI编码工作流应采用双层协作:大语言模型负责意图理解与方案探索,编译器、静态检查等确定性工具负责执行与校验。让大语言模型去做可确定性计算的工作,是浪费,也是风险。
Harness体系:连接AI与工程系统的适配层
解决非确定性问题的核心是构建Harness体系。一个公式理解其位置:Agent = 模型 + Harness。它涵盖沙箱环境、状态管理、验证机制、权限管控等模块,可拆解为三部分:事前引导(规则文档、架构边界、任务模板)、事后感知(测试、日志、错误分类)、持续清理(旧代码与无效规则的迭代删除)。
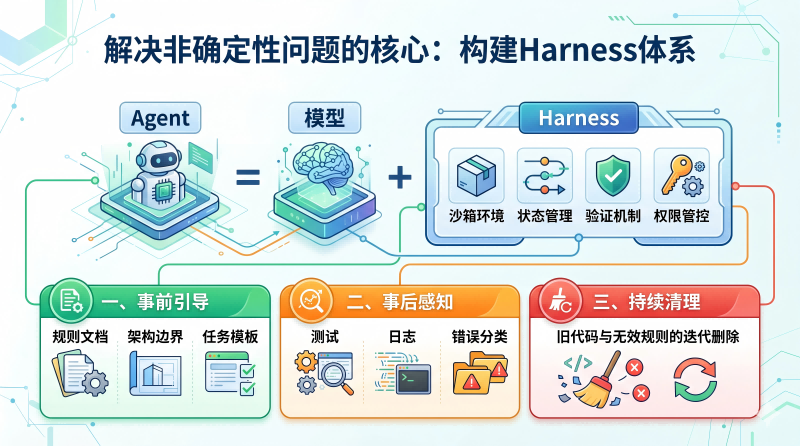
权限管控是其中的核心。低风险操作自动执行,中风险操作人工确认,高风险操作强制审批与审计。AI生成内容的最大风险在于用流畅表述掩盖逻辑缺陷,安全感不能来自模型的输出语气,必须依托测试执行、类型校验等外部可量化反馈。
工程师的角色在变,价值没有降低
AI替代了代码编写等重复性工作,工程师的核心职责从直接编码,转向任务定义、模型监督、输出评估、错误规则沉淀。控制点从代码编辑,转移到目标规划、边界设定、权限管控、系统演进。
代码生成成本降低后,架构设计、风险验证、安全治理的重要性反而被放大。软件工程的整体复杂度没有降低,对工程师系统设计与管控能力的要求只会更高。
结语
AI研发的正确方向,不是脱离工程规范的自动化,而是把工程经验沉淀为系统规则,让AI在可控边界内稳定发挥价值。从轻量化任务拆分、验证体系搭建、权限规则配置这些细节入手,逐步构建适配AI的工程体系,效率与质量的平衡才真正可持续。
相关课程:
| 联系人: | 田老师 |
|---|---|
| 电话: | +86 135 5227 9573 |
| Email: | clientservice@hardenx.cn |
| 地址: | 北京市朝阳区福码大厦B座17层1705 |


加微领1G资料
